この記事では、PythonでExcelファイルを書き込む方法を解説します。
他の形式のファイルを扱うには以下の記事を参照してください。
| CSVファイルを読み書きする方法 |
| open関数を使ってファイルを読み書きする方法を解説 |
| 一時ファイルを扱う方法 |
また、Excelファイルを読み込む方法は以下の記事を参照してください。
ライブラリのインストール
PythonでExcelファイルを読み込むには、pandasを使います。まだ、インストールしてない方は以下のようにインストールしましょう!
$ pip install pandas依存関係としてopenpyxlも必要となります。
$ pip install openpyxlインポート
ソースコードの先頭でpandasをインポートします。
import pandas as pdasを使って「pd」と別名を付けて使用されることが多いです。
Excelファイルを書き込む
Excelファイルに書き込みたいデータをDataFrameオブジェクトとして準備します。
df = pd.DataFrame( [ ['Bob', 24], ['Mike', 39], ], )次に、ExcelWriterクラスのインスタンスを生成します。
引数には書き込むファイルの名前(パス)を指定します。
writer = pd.ExcelWriter('test.xlsx')そしたらDataFrame.to_excel()を使ってExcelシートに書き込みます。
引数には先ほど生成したExcelWriterオブジェクトを指定します。
df.to_excel(writer)書き込みが終わったら生成したExcelWriterオブジェクトを閉じます。
writer.close()最終的なコードは以下のような感じになります。
import pandas as pd df = pd.DataFrame( [ ['Bob', 24], ['Mike', 39], ], ) writer = pd.ExcelWriter('test.xlsx') df.to_excel(writer) writer.close()上記コードを実行すると同ディレクトリ内に以下のようなExcelファイルが生成されます。

ExcelWriterオブジェクトは後処理が必要なのでwith文で扱うとより安全です。
import pandas as pd df = pd.DataFrame( [ ['Bob', 24], ['Mike', 39], ], ) writer = pd.ExcelWriter('test.xlsx') with pd.ExcelWriter("test.xlsx") as writer: df.to_excel(writer)indexやcolumnsの指定
DataFrameオブジェクトのindex引数やcolumns引数にあらかじめ任意の値を渡しておくことでindexやcolumnsを指定することができます。
import pandas as pd df = pd.DataFrame( [ ['Bob', 24], ['Mike', 39], ], index=[1000, 1001], columns=['name', 'age'], ) with pd.ExcelWriter("test.xlsx") as writer: df.to_excel(writer)実行結果は以下のようになります。

indexやcolumnsを書き出したくない場合は、DataFrame.to_excel()のindex引数やheader引数にFalseを指定する。
import pandas as pd df = pd.DataFrame( [ ['Bob', 24], ['Mike', 39], ], ) with pd.ExcelWriter("test.xlsx") as writer: df.to_excel(writer, index=False, header=False)実行結果は以下のようになります。
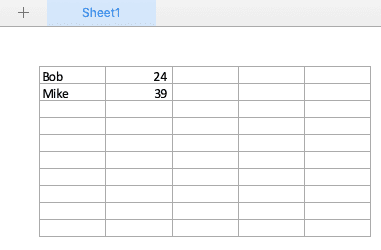
シートの指定
DataFrame.to_excel()のsheet_name引数にシート名を指定することで書き込むシートを変更することができます。
import pandas as pd egg = pd.DataFrame( [ ['美味しいたまご', 185], ['高いたまご', 500], ], columns=['name', 'price'], ) natto = pd.DataFrame( [ ['ネバネバすぎる納豆', 159], ['匂う納豆', 289], ], columns=['name', 'price'], ) with pd.ExcelWriter("test.xlsx") as writer: egg.to_excel(writer, sheet_name='egg') # シート名にegg natto.to_excel(writer, sheet_name='natto') # シート名にnatto以下のような2つのシートが生成され、データが書き込まれます。
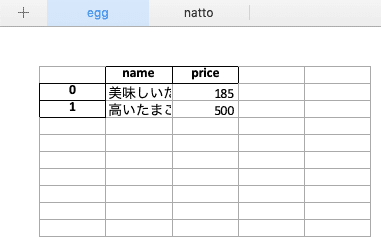
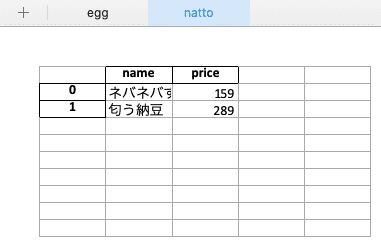
追記
ExcelWriterオブジェクトのmode引数に'a'を指定することで追記モードでシートを書き込むことができます。
# test.xlsxにsheet2を追記 with pd.ExcelWriter("test.xlsx", mode='a') as writer: df2.to_excel(writer, sheet_name='sheet2')既に存在するシートに書き込もうとする場合(シート名を指定しない際も同様)はif_sheet_exists引数を変更する必要がある。if_sheet_exists引数は既に存在するシートに書き込もうとする際の動作を定めています。
以下のような動作を指定可能です。
| error | ValueErrorを発生させる。 |
|---|---|
| new | エンジンによって決定された名前で新しいシートを作成します。 |
| replace | シートに書き込む前に、シートの内容を削除します。 |
| overlay | 古いコンテンツを削除せずに、既存のシートにコンテンツを書き込みます。 |
では、試しに'new'で追記してみます。
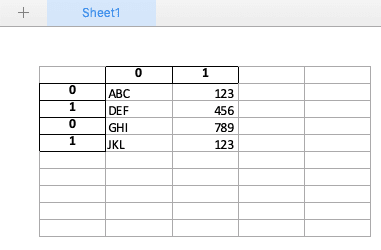
import pandas as pd df1 = pd.DataFrame( [ ['ABC', 123], ['DEF', 456], ], ) df2 = pd.DataFrame( [ ['GHI', 789], ['JKL', 123], ], ) # Excelファイルの生成 with pd.ExcelWriter("test.xlsx") as writer: df1.to_excel(writer) # 追記 with pd.ExcelWriter("test.xlsx", mode='a', if_sheet_exists='new') as writer: df2.to_excel(writer)以下のように新たにシートが追加され、データが書き込まれました。

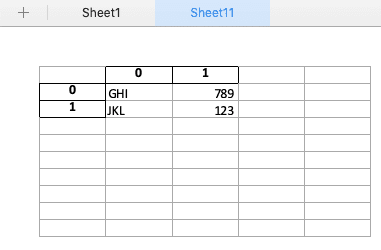
同じシートに追記したい場合は、if_sheet_exists引数をoverlayに指定し、DataFrame.to_excel()にstartcol引数やstartrow引数で書き込み始める場所を指定します。
また、indexやcolumnsが邪魔ならindex引数やheader引数にFalseを指定しておきます。
import pandas as pd df1 = pd.DataFrame( [ ['ABC', 123], ['DEF', 456], ], ) df2 = pd.DataFrame( [ ['GHI', 789], ['JKL', 123], ], ) # Excelファイルの生成 with pd.ExcelWriter("test.xlsx") as writer: df1.to_excel(writer) # 追記 with pd.ExcelWriter("test.xlsx", mode='a', if_sheet_exists='overlay') as writer: df2.to_excel(writer, startrow=3, header=False)実行結果は以下のようになります。